Introduction
Amazing URL Shortener is an online tool with high availability to shorten a long link and provide detailed statistics.
Demo:
username: test
password: test
Short link demo: urls.fit/a26B4EM0
GitHub repo:
- Backend: https://github.com/leihehehe/java-url-shortener
- Frontend: currently is a private repo
Technical Stacks Used
Backend Techniques:
Framework: SpringBoot, Spring Cloud
Gateway: Spring Cloud Gateway
Message Queues: RabbitMQ, Kafka
Database-related Techs: Redis, Redisson(operating on Redis), ClickHouse, SpringData JPA, MySQL, Apache Shardingsphere
Data Streaming-processing Framework: Flink
Availability: resillience4j
Others: Openfeign, etc.
Frontend: Angular.js
DevOps:
- Jenkins
- Kubernetes
ShardingSphere
ShardingSphere provides a distributed database solution based on the underlying database, which can scale computing and storage horizontally
Why use it?
Since we are developing a system that can handle massive data, it is not possible to just use one single database or a few tables to store the data. Storing massive data in only one node or database will cause much pressure on the database itself, and speed will be significantly slowed down.
Therefore, it is necessary to do sharding and partitioning. For example, I divided the product_order table into two tables stored in the url_shop database and divided the short_link table into 6 tables and every two tables are distributed in a url_link table. (For more details, please see the Database Structure part)
Partition Keys
Partition keys are set in terms of different cases. For example, for users to find their orders quickly, accountNo is used as a partition key, so that a user’s orders will be in the same table.
Another situation is that we need to handle a large number of shortened links across multiple databases and tables. In this case, I use accountNo as a partition key to finding out which databases the records are currently in. Besides, groupId is used as a partition key for finding out which tables the records are currently in.
How to query the data in this case?
I used two methods to query the data
- Modulo. For example,
k = accountNo mod nwhere n is the number of tables that will query the kth table - Store database and column info in the data itself. For example, we got a short link code stored in the database
aand table2, then we can update the short link code toaxxxx2, so that we could quickly locate this short link when querying the data.
Redis, Redisson & Lua Script
- Redis is used as a cache in the project. It stores the users’ plan data information to prevent frequent requests to the MySQL database.
- Redis and Redisson are used together to handle distributed locks. In addition to using Redisson, Lua script is also straightforward and used for creating locks.
RabbitMQ
- RabbitMQ is used to slow down the response waiting time as operations can be asynchronously executed by sending messages.
- RabbitMQ is also used to deliver delayed messages for different purposes like order cancellation and distributed transactions.
- Compared to
Kafka, it is more suitable for an e-commerce business service(e.g. scheduled tasks and distributed transaction management)
Flink, Kafka & ClickHouse
Flink is used for processing data streams at a large scale and to deliver real-time analytical insights about your processed data with your streaming application.
In this project, I used Flink to get visitor information when a visitor is trying to access a shortened link. Flink helps to process the visitor information in each layer and pass the processed information to the next layer using Kafka.
At the last layer, I used Flink to pass the final datasets to ClickHouse which is a fast column-oriented database management system.
ClickHouse allows us to generate analytical reports using SQL queries.
Jenkins & Kubernetes(High Availability)
The Jenkins file is included in the project, and both front-end and back-end projects are deployed using Kubernetes and Jenkins.
Jenkins runs a piepeline to build and upload images to AWS ECR.
Using 3 servers(1 master node and 1 worker node) to build a Kubernetes cluster.
Technical Difficulties & Solutions
Creating Short URLs
There are two options.
Snowflake ID + Base62 Encoding. For example, first we use
SnowFlaketo create a unique ID, then pass the resulting ID to a Base 62 encoding function. This will give us a unique link.Pros: It ensures that every original url can produce a unique short url.
Cons:
- We have to make sure that all the machines having the same system time configured.
- If the Snowflake generated ID is long, the resulting short path, even after Base62 encoding, may not be sufficiently short.
But there is still a possibility of two users generating the same short link when they creating the short link at the same time(within 1ms).
Snowflake ID + MurmurHash + Base62 Encoding. Compared to the first option, we use
MurmurHashto hash our unique id, to make it shorter enough, then we use Base62 encoding.Pros: we can generate shorter links.
**Cons: **
- All hash algorithms have the potential for hash conflicts. Although MurmurHash has a low conflict probability, it cannot guarantee complete conflict avoidance.
- You can’t recover the original ID from the short path(but it does not matter in our case)
To avoid hash conflicts, we can
- Retry with Variation: If a collision is detected, modify the input slightly (e.g., by adding a counter or changing a bit in the original ID) and regenerate the hash. Repeat this process until a unique short path is generated.
- Salting: Introduce a salt—a random value added to the input of the hash function—to ensure that even if the original IDs are similar, the resulting hashes will be different. For example, we can add SnowFlake ID appended to the original url, and hash it again.
Database Sharding and Partitioning
As we know users prefer to query links in terms of their accountNo, if the links are distributed in different databases and tables, it will be very difficult for users to query the data since the system needs to access all the databases and tables to get the records.
However, visitors, just need the short link code to locate tables so that they can get original urls quickly. But they have no idea about the groupId and accountNo.
So apparently, we would have two different partition keys to deal with these two cases.
Therefore, I duplicated the tables so that tables group_link_mapping are used to store data for users, short_link tables are used to store data for visitors.
Distributed Transaction Management
New issues have arisen after duplicating the short link tables. Since tables need to be synchronized, there will be inconsistent data if the operation on the user side failed but succeed on the visitor side.
There are two solutions
- Message Queue: When we are trying to insert data, we send a message to a queue using
RabbitMQ. The first table will retrieve the message and perform the insertion operation. If it fails, the second table will not do anything. If it succeeds, it will send another message indicating that the insertion was successful, and then the second table will perform the insertion. If the second table fails or succeeds, it will send a message, so that the first table can check if it needs to be reverted. - Delayed Message Queue: Use
RabbitMQto send a delayed message to check if operations on both sides are successful.
Two Users Creating the Same Short Link
If two users are generating the same short link, user A has inserted data to group_link_mapping and user B has inserted data into short_link, at this time, both users will fail because they cannot insert data into others tables(data already exists).
Solution: Use Redis to add a lock. The value stored in the Redis will be accountNo, if accountNo in the Redis matches the current logged-in accountNo, continue the operations. Otherwise, stop the operations(another user is holding the lock).
Nginx - Short Link Access and API server
Updates:
I have changed the Load balancer to Nginx. Using Nginx can help us load balance and proxy traffic to bankend servers. It significantly saves the overhead of using the AWS load balancer.
I used the Load Balancer in AWS to forward different requests with different URLs and the specific port (80). Basically, we will have two different domains for websites and shorten urls.

Eureka Servers
I did not deploy Eureka servers to Kubernetes. Instead, I deployed them to another machine and used Docker network functions to enable communication between them.
Database Structure (ER Diagram)
url_shop

url_link_0
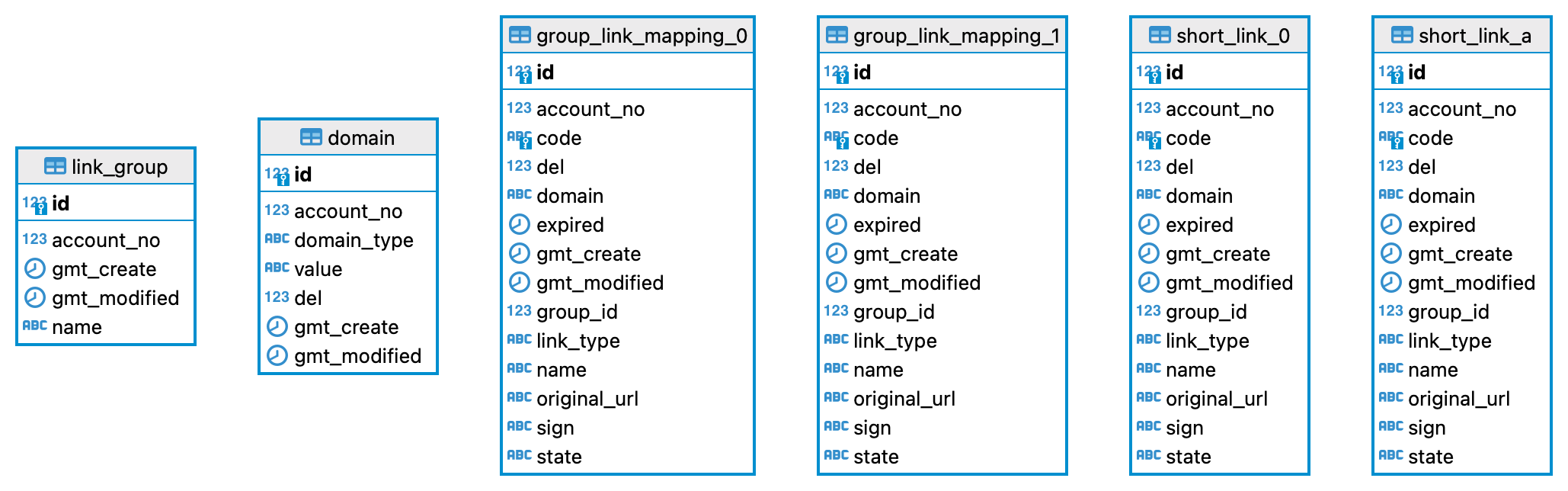
url_link_1

url_link_a
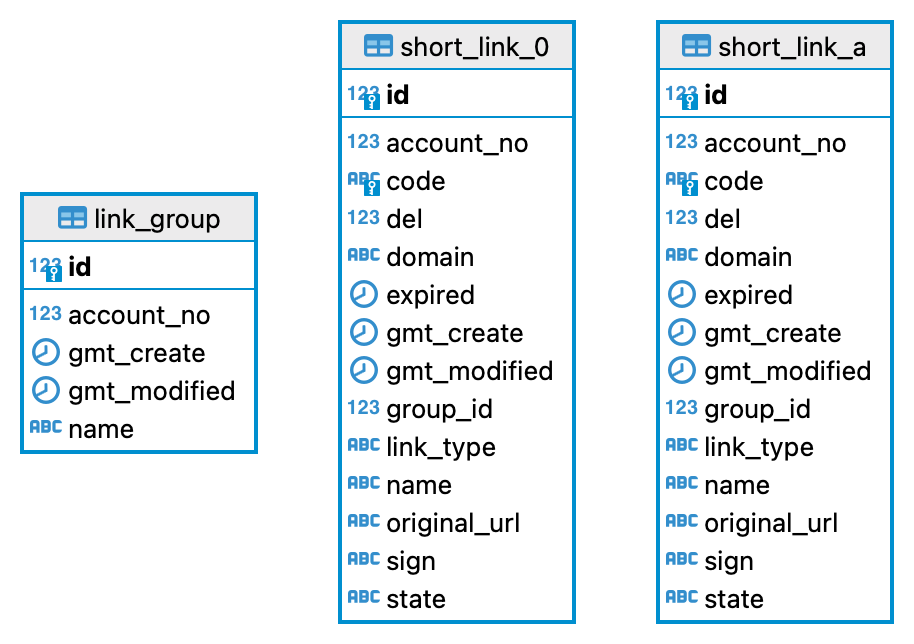
url_shop
